
*文章授权转自微信公众号「CG世界」
最近,来自迪士尼研究中心的的专业人士发布了一种面部表情捕捉的新方法,既不需要贴任何标记点,也不需要跟踪牙齿,只需要演员头部的图像脚本,就能准确跟踪到下颌的运动方式。
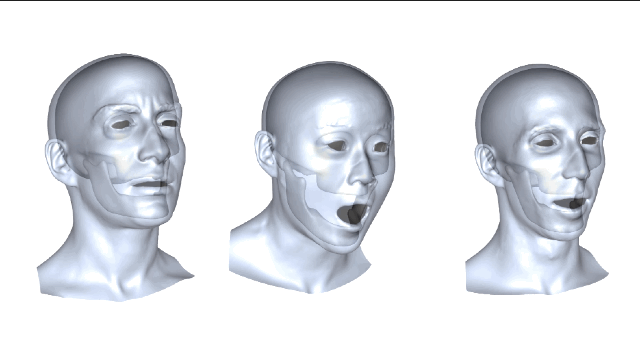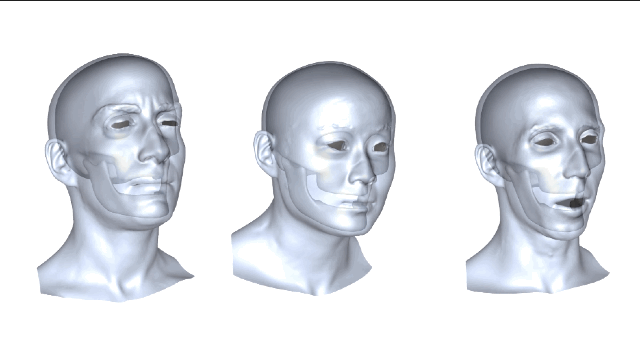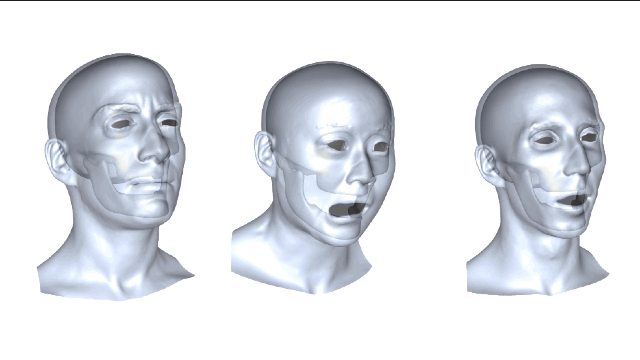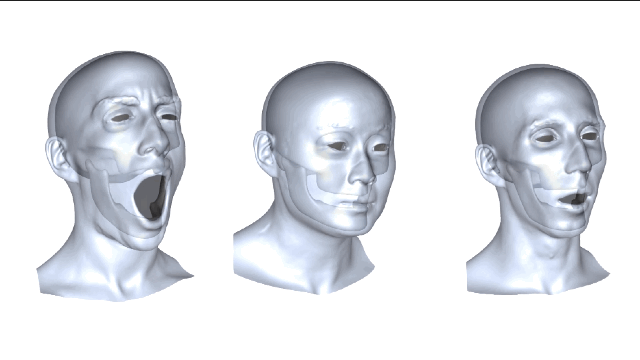
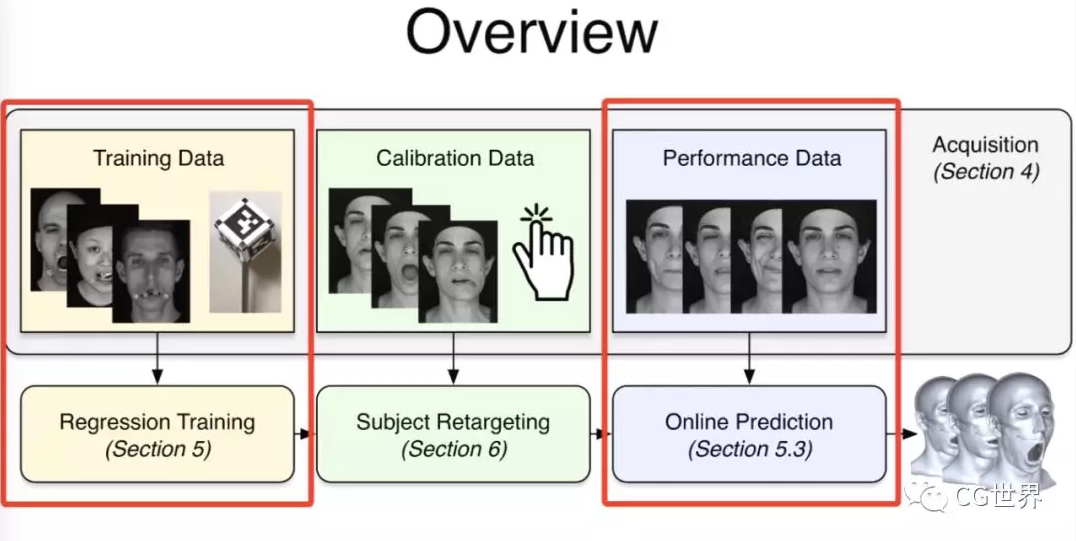
这种新方法简而言之,就是利用数据集里下颌动作的真实数据来学习从皮肤变形到下颌运动的非线性映射,并把映射重定向到新目标主体上的一个过程。这么解释好像说得还是不太明白,咱们仔细来看看。
在正式进入主题之前,咱们得引入一个传统的制作方法“基线法”。
所谓“基线法”就是指,艺术家完全依靠手动操作或者是把下颌线周围的皮肤运动大概粗略地等同于下颌运动,并且忽略了皮肤滑动产生的不精准效果。误差还不小呢。
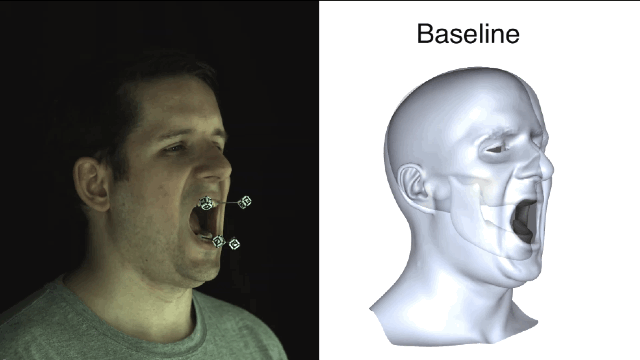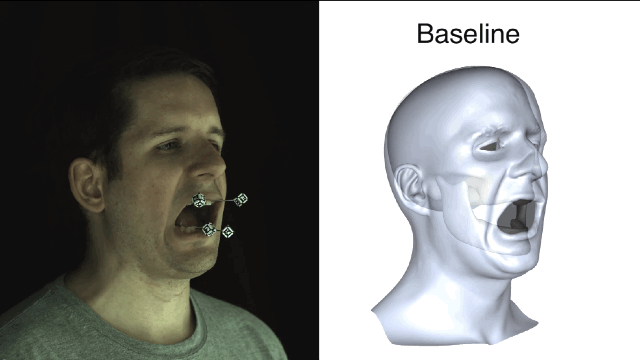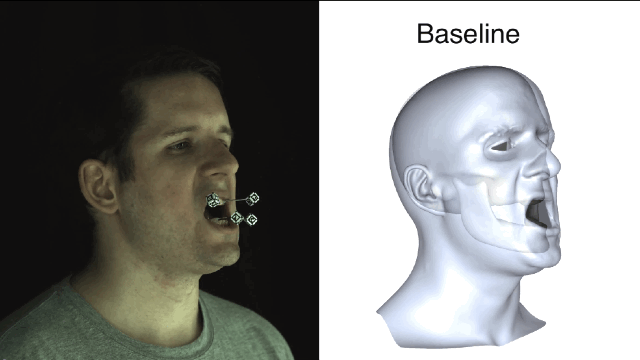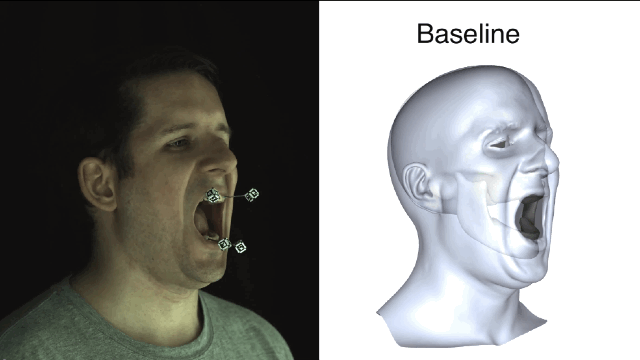
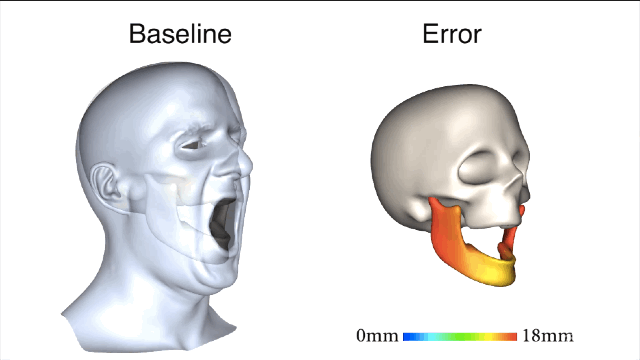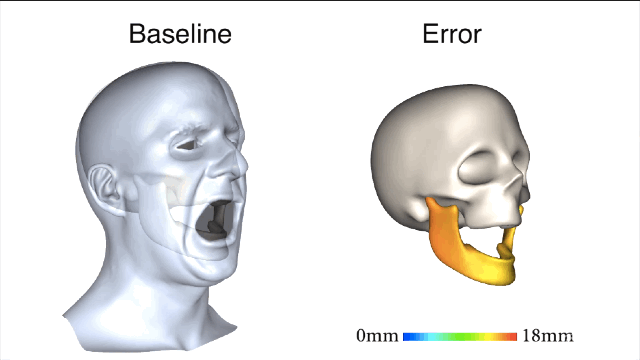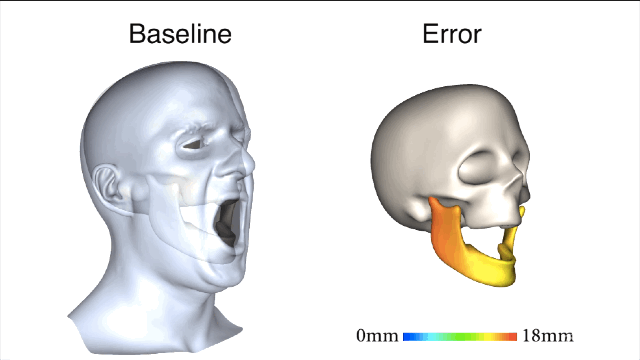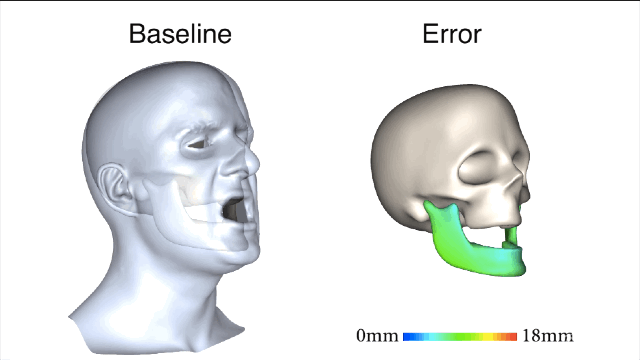
清楚了蛤?好,咱们开始进入正题。新方法一开始要先用基准标记来捕捉真实有效的训练数据,获取以帧为单位的精确下颌姿势和面部重建结果。
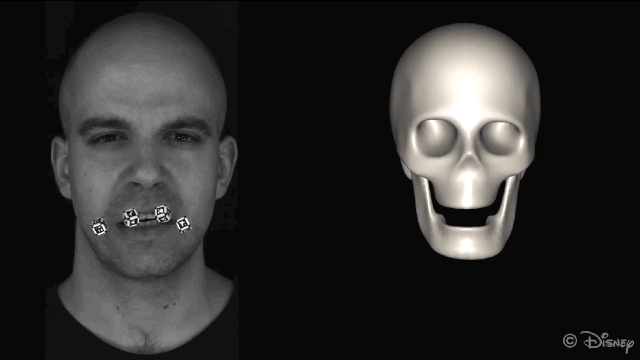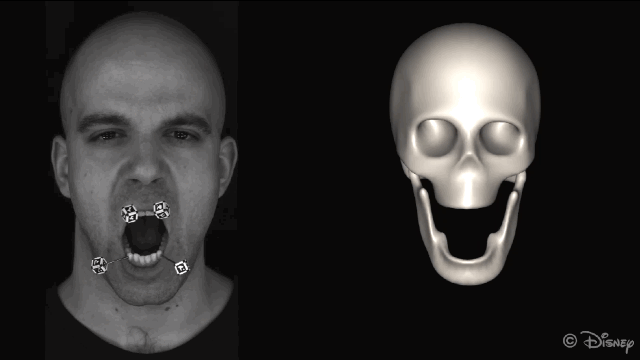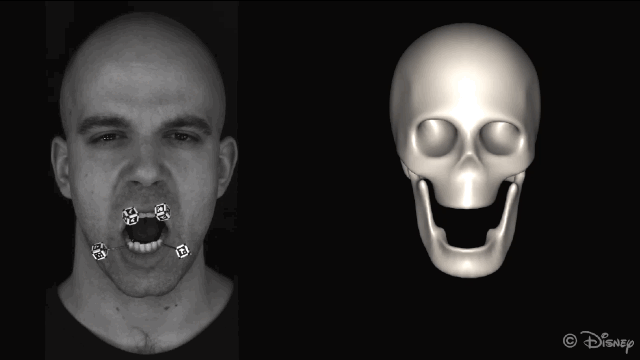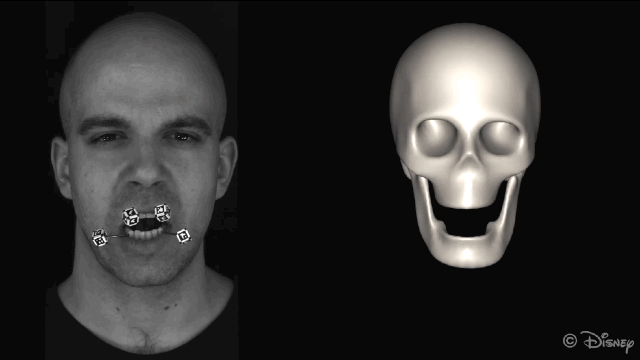
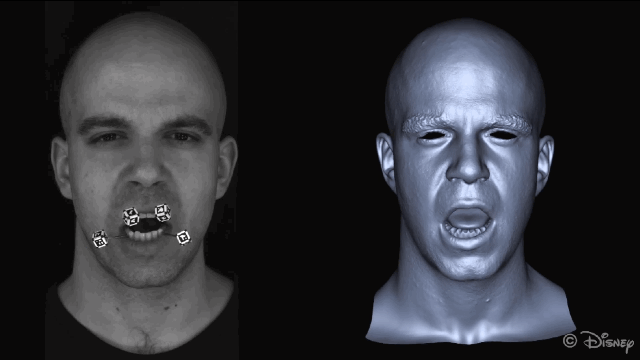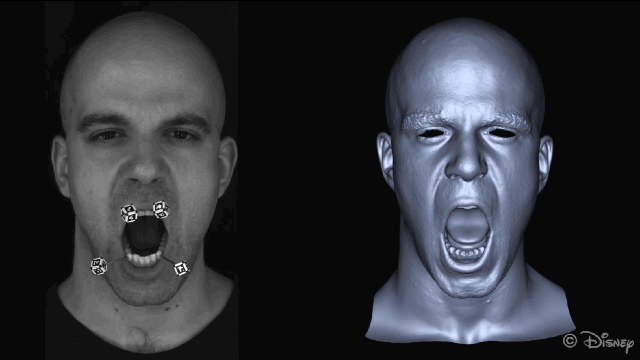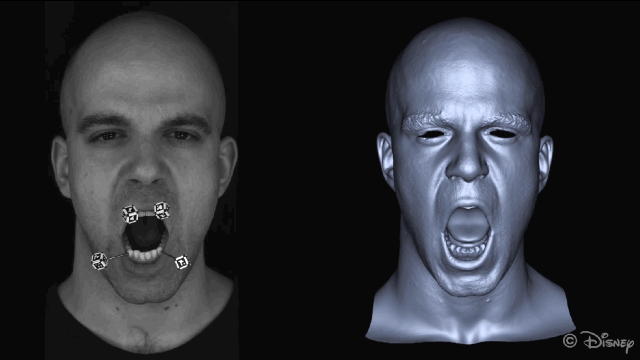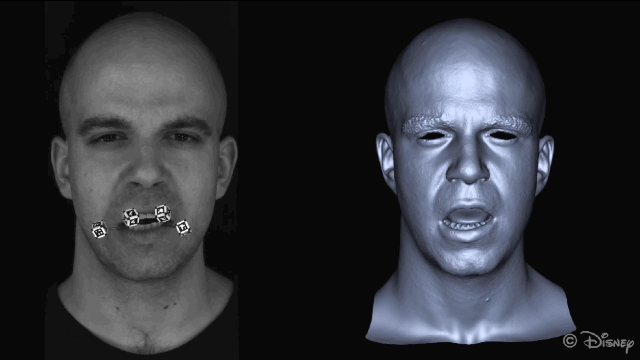
为了获得准确的面部运动,在重建面部之前会自动屏蔽图像中的标记点。
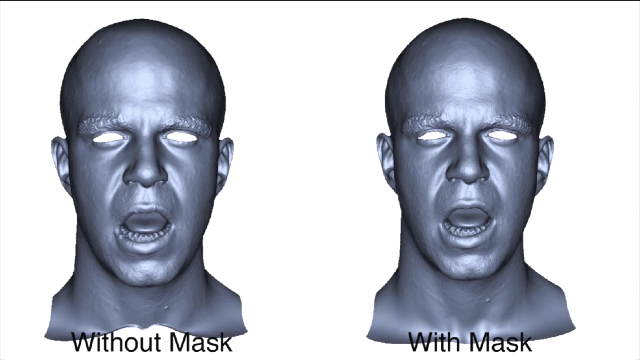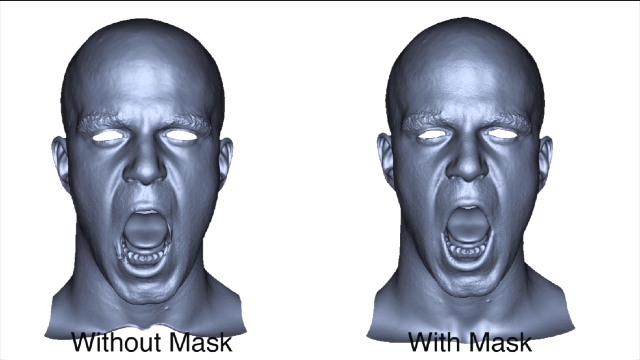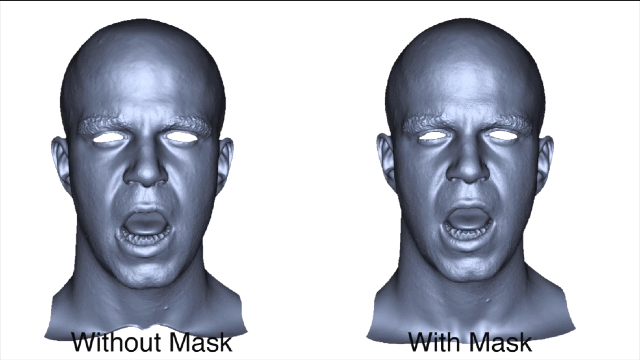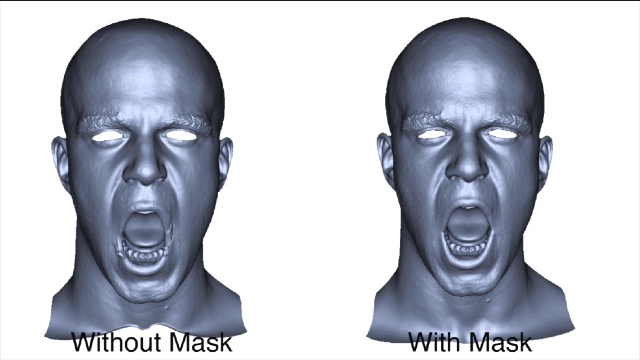
在得到训练数据之后,就可以训练一个序列并对相同主体测试新序列,通过这个过程来检测基于回归的任务预测是否是准确的。
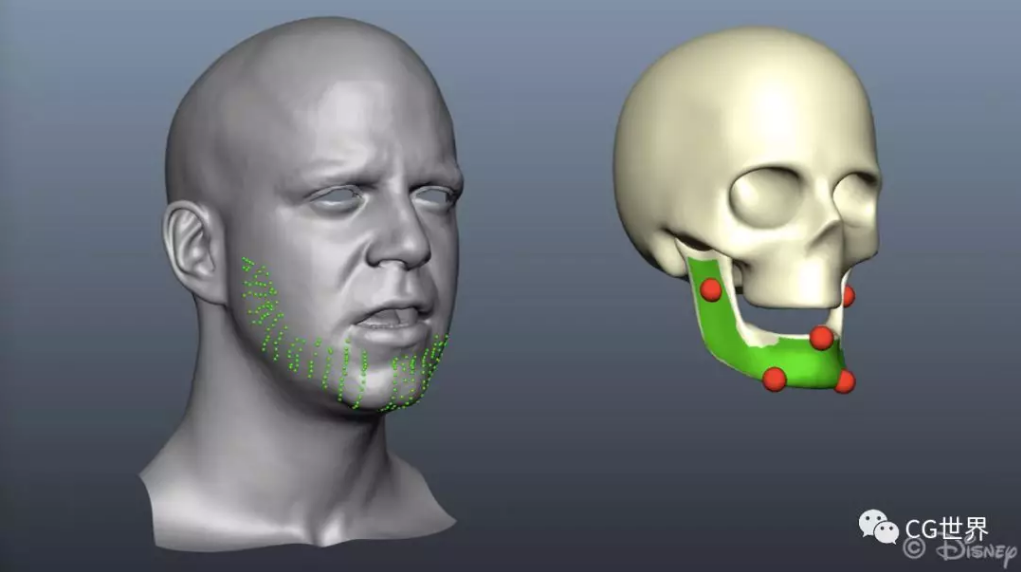
新方法的核心理念是利用皮肤和下颌运动之间的关联。为了实现这种关联,研究人员从一组皮肤表面特征(脸上显示的绿色部分)和一组下颌骨移动的特征(头骨上红色的部分)来学习非线性映射。
新方法和基线法之间的对比就一目了然了,新方法所产生的误差值要小很多。
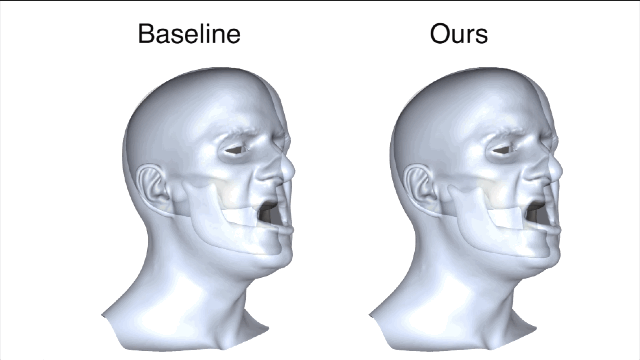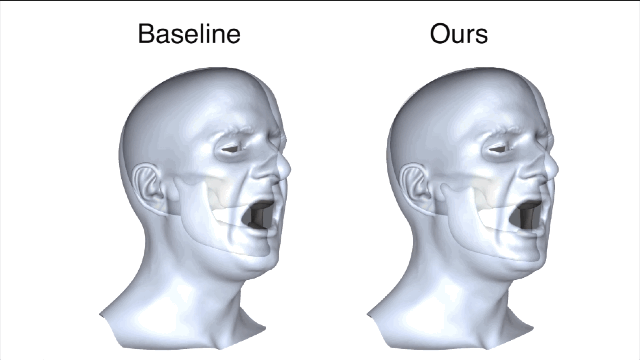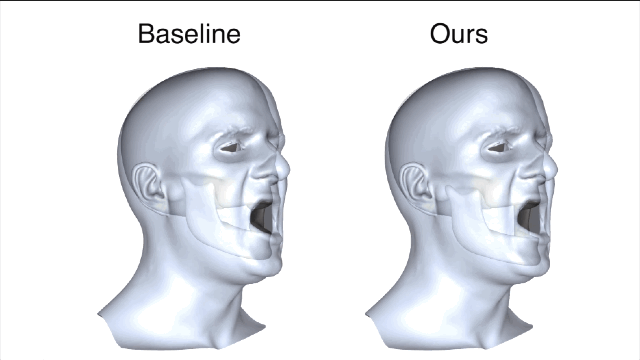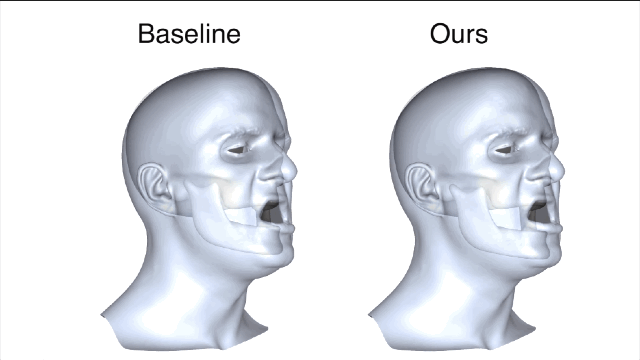
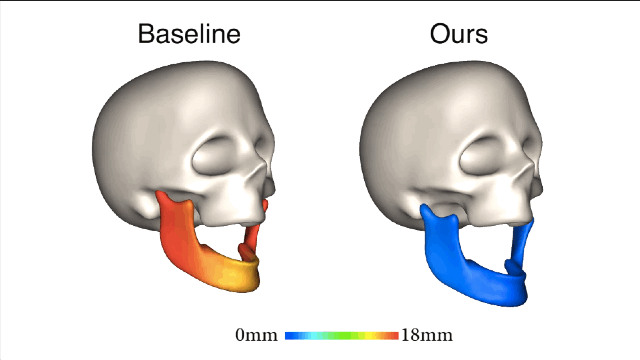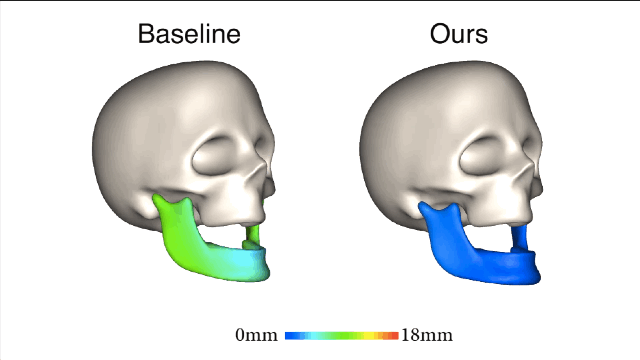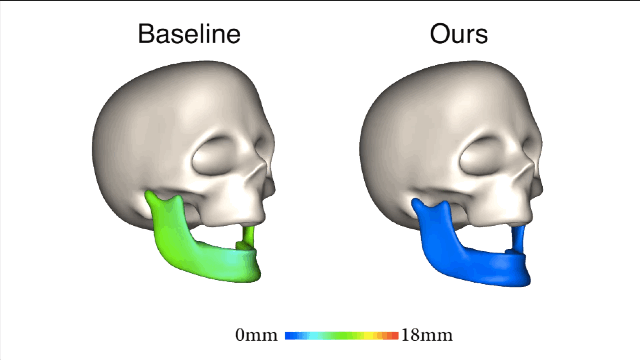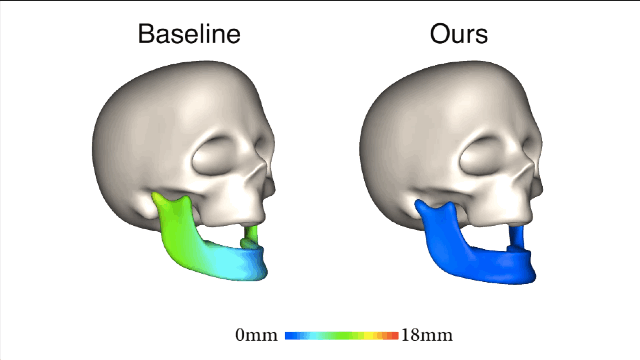
在相同主体上进行的训练和测试都是要基于真实有效的数据。
而新方法的厉害之处在于,它属于一种对于目标主体的新型重定向,而不是训练集中的某个部分。
此外用几个动作也可以来校准已知的下颌动作,通过对图像下边的牙齿进行三角测量就能获得这些动作,通过计算将每个特征和动作进行匹配,和训练预测时的输入特征相一致,然后再映射到另一位演员脸上就可以了。可能有小伙伴会问到映射重定向具体是怎么进行的呢?这里有一篇研究人员的论文,感兴趣的话可以啃一啃(链接在文末)。



我们再来比较一下,从3个不同主体映射到演员面部的结果,左边是“基准法”,中间是演员自身的,右边是重定向方法的,误差大小都可以看出来了吧。 新方法与演员主体特定训练之间的误差是非常接近,这两种预测方式都极大地优于“基线法”。
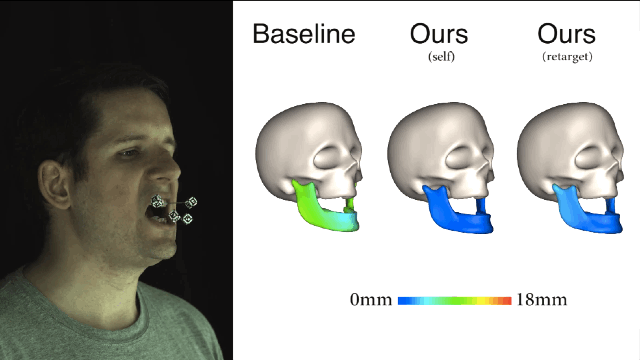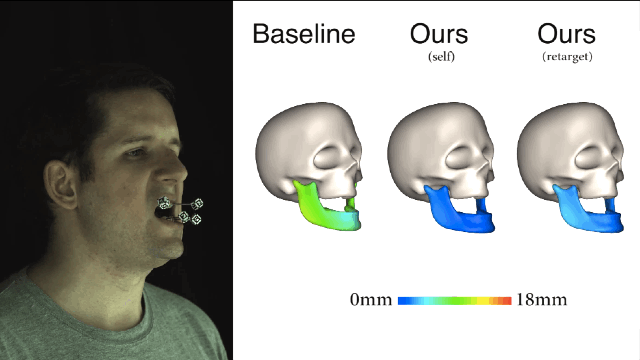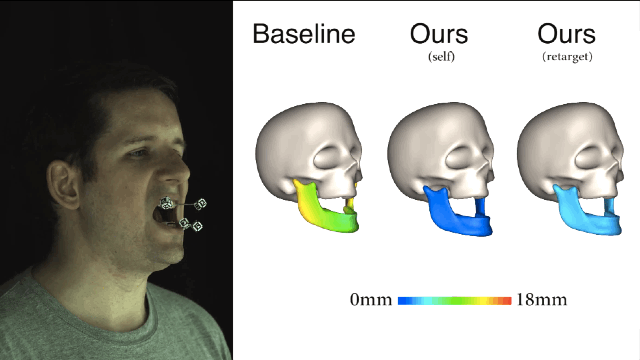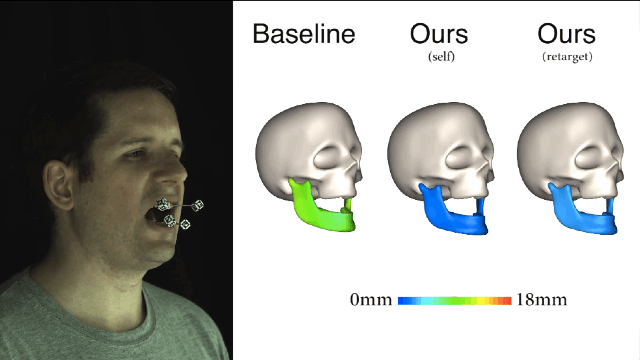
重定向的新方法很容易地就能和现有的面部表情捕捉系统集成,让依靠体力劳动而且极易出错的捕捉过程实现自动化。希望这样的方式在未来可以应用到实际的项目制作当中。
好啦,关于这项技术就先介绍到这里吧,感兴趣的小伙伴可以拿到迪士尼研究中心的论文研究一下哈~
链接:
https://pan.baidu.com/s/1zPePjGniH9ygd30JhJMkkA
密码:yurp
欢迎关注作者的微信公众号:「CG世界」

加载中