
我们之前好像介绍过将低分辨率视频利用AI处理后变成高分辨率技术的文章,依稀记得是去年时候。但那个只是让分辨率提高,而物体的细节其实还是相对粗糙的。今天介绍这个新技术是让模糊的,变清晰,把视频中物体细节也能补回来的技术,听起来是不是很厉害?一起来看看厉害在哪里。

这是一篇论文,论文名字叫《Learning Temporal Coherence via Self-Supervision for GAN-based Video Generation 》翻译过来大致意思是《基于自我监督学习时间相干性的GAN视频生成》简称“TecoGAN”。看着很复杂的样子,其实它的作用描述起来很简单,就是将输入的一个劣质视频,通过这个技术分析它,然后输出一个高分辨率的清晰视频。

别说视频哈,就是对于一幅静止图像来说这也是是一个非常难问题。之前在AI技术不如今天这样发达的时候,基本是通过手工制作的技术来处理的,这种局限性可想而知了。本来画面都看不清,你手动制作技术如何修复的更好呢?还有就是效率问题等等吧。
那有了今天这个TecoGAN正好就都解决了。除了图片,这种技术而且还可以很好地处理视频。

那么这个算法是如何实现的呢?打个比方哈,当我们看见一个模糊的角色眼睛时,眼睛反射的物体可能有绿色的,蓝色组成。把这个描述说给一个人,那么立马会理解这个描述说的是另一个人的眼睛,大致就知道了在现实中应该是什么样子。但是对于电脑呢?如果我们有一个学习算法,也可以以这样的思维方式思考和观察同一个视频的粗略和精细版,学习后,你给它个模糊的视频时,就会给你创建一个超高分辨率且细节到位的视频呢,这就是TecoGAN技术发生的过程,明白了么?
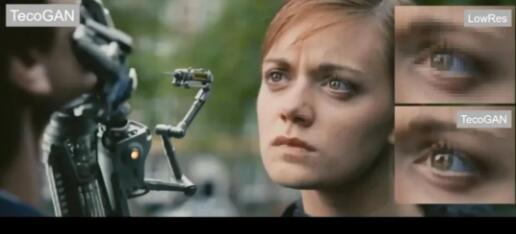
看下面这个动图,其中给它提供很少的视频画面信息,而它能够为其添加大量的细节。

当然了,研究超高分辨率这个领域技术的大有人在。那么和这个TecoGAN相比好在哪里呢?我们拿其他技术和这个技术实现的效果来对比下就知道了。
下面这张图是用来测试的一张模糊图片。




好多细节全部都添加进去了,真的很强啊
其实,generativecontainarial networks,GANs(生成对抗性网络)在学习复杂分布(如自然图像)方面取得了极大的成功。然而,对于序列生成,由于时间变化所带来的困难,直接应用没有精心设计约束的GANs通常会随着时间的推移而产生强烈的伪影。特别是,条件视频生成任务是一个非常具有挑战性的学习问题,其中生成器不仅要学习表示目标域的数据分布,而且还要学习将输出分布随时间的变化与条件输入相关联。它们的中心目标是忠实地再现目标域的时间动态,而不是求助于琐碎的解决方案。
针对这种状况几位研究人员提出了一种新的对抗性学习方法,用于监督空间内容和时间关系的循环训练方法。将这种方法应用于两个视频相关的任务,它们提供了本质上不同的挑战:视频超分辨率(VSR)和未成对视频翻译(UVT)。在没有真实标准运动的情况下,时空对抗损失和递归结构使模型能够产生真实的结果,同时保持生成的结构随时间保持一致。

以上这个论述是摘自论文中的,比较学术,不懂也没关系。前面我描述的懂了,就可以了。
每次论文解析,大家都会异口同声的说,只是论文又不能用。哎?话不要说的太死!今天这个就可以操作玩一下。但是这里我就不讲过程了,大家自己去试试吧。
https://github.com/thunil/TecoGAN
这个链接里有源代码,和使用过程,就是需要懂编程的能快点看懂。此外硬件要求必须具有CUDA的Nvidia GPU才可以,Emmm只能帮到这里了,其他大家伙自己玩吧。

论文作者:Mengyu Chu、You Xie、Laura Leal-Taixe、Nils Thuerey。
论文地址:https://arxiv.org/pdf/1811.09393.pdf
参考视频:https://www.youtube.com/watch?v=MwCgvYtOLS0
*文章授权转自微信公众号「CG世界」

加载中